[Paper Review] SimCLR: A Simple Framework for Contrastive Learning of Visual Representations
오늘 소개할 SimCLR은 Self-supervised learning(SSL) 방법을 사용하는 모델입니다. Self-supervised learning은 데이터 자체로부터 파생된 proxy label을 예측해 데이터 embedding을 학습하는 방식입니다. Vision 분야의 대표적인 SSL 방법은 크게 세 가지로 나누어 볼 수 있습니다.
Context Based이미지 내의 작고 구체적인 정보를 가리고 복원합니다. 이미지를 회색으로 바꾸거나, 이미지를 패치로 나누어 섞어서 proxy label을 만듭니다.Contrastive learning같은 이미지 쌍의 거리는 가깝게, 다른 이미지 쌍의 거리는 멀어지도록 embedding을 학습합니다.Masked Image Modeling큰 패치 전체를 무작위로 최대 80%까지 가리고 복원합니다.
SimCLR은 이 중에서도 Contrastive learning에 속하는 모델입니다. 이전 연구들과는 다르게, 복잡한 구조나 memory bank 없이도 높은 성능을 달성했습니다.
2. SimCLR 모델 구조
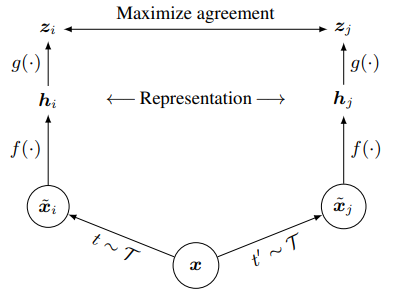
앞서 언급했던 것처럼, SimCLR은 매우 단순한 구조로 되어 있습니다.
Step 1input $x$가 입력되면, 서로 다른 data augmentation을 거쳐 $\tilde{x_i}$와 $\tilde{x_j}$를 만듭니다. 논문에 따르면, random cropping, random color distortions, random Gaussian blur를 조합했을 때 가장 우수한 성능을 보였다고 합니다. 두 데이터 $\tilde{x_i}$와 $\tilde{x_j}$는 동일한 input $x$으로부터 나왔기 때문에 positive pair입니다.Step 2Encoder $f(\cdot)$를 거쳐 representation $h_i$와 $h_j$를 얻습니다. 이 때, Encoder로는 ResNet-50을 사용합니다.Step 32-layer MLP와 ReLU로 구성된 nonlinear transformation $g(\cdot)$을 거쳐서 $h$를 $z$ space에 매핑합니다. 이 부분은 representation의 품질을 높이는 데 중요한 역할을 합니다.Step 4NT-Xent loss를 최소화하도록 학습이 진행됩니다.
NT-Xent loss
\[\mathcal{L}_{i,j} \;=\; -\log \frac{\displaystyle \exp\!\bigl(\operatorname{sim}(z_i, z_j)/\tau\bigr)} {\displaystyle \sum_{k=1}^{2N} \mathbf{1}_{[k \neq i]}\, \exp\!\bigl(\operatorname{sim}(z_i, z_k)/\tau\bigr)}\]NT-Xent는 Normalized Temperature-scaled X-entropy의 약자입니다. 수식 자체는 2018년 발표된 논문 Representation Learning with Contrastive Predictive Coding에서 제안된 InfoNCE와 동일한 형태입니다. l2 normalization과 temperature를 강조하기 위해 NT-Xent라고 명명한 것입니다.
위 수식에서 분자는 같은 이미지로부터 나온 positive pair $z_i$와 $z_j$의 유사도이고, 분모는 자기 자신 $z_i$를 제외한 모든 pair의 유사도 입니다. positive pair의 유사도가 커질수록, negative pair의 유사도가 작아질수록 loss가 작아집니다. 모든 pair에 대해 양방향 계산 $(i, j), (j, i)$을 하므로, 배치 사이즈가 $N$일 때, $2N$개의 loss를 계산하게 됩니다.
$\tau$는 softmax 분포의 뾰족함을 결정합니다. 이 값이 작을수록 작은 유사도 차이도 크게 확대되어 구분하기 어려운 hard negative pair에 가중치를 주게 됩니다. 반대로 $\tau$가 크면 softmax 분포가 완만해져서 안정적인 학습이 가능해집니다. 데이터와 배치 크기에 따라 최적값이 달라지지만, 논문에서는 $\tau$가 0.07일 때 가장 좋은 성능을 나타냈다고 합니다.

3. 모델 성능
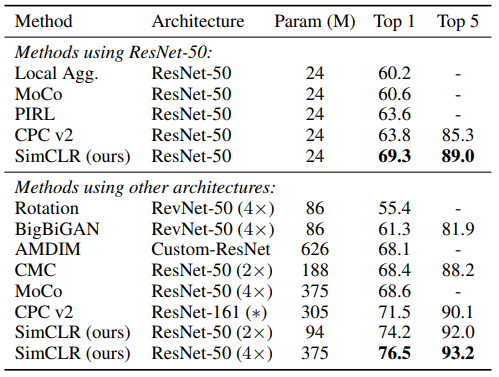
위 표는 다른 self-supervised 방법들과 ImageNet 분류 성능을 비교한 결과입니다. 다른 방법들에 비해 SimCLR이 높은 성능을 보이는 것을 확인할 수 있습니다.