[Paper Review] Deep Residual Learning for Image Recognition
[Paper Review] Deep Residual Learning for Image Recognition
ResNet 등장 배경
- 모델이 깊을수록 학습하기 어려움
- layer를 깊게 쌓을수록 모델이 보다 풍부한 feature를 학습할 수 있기 때문에 vision task에서 모델의 깊이는 모델의 성능을 결정짓는 매우 중요한 요소로 여겨짐
VGGNet도 3x3 크기의 작은 filter를 사용하여 layer를 깊이 쌓아AlexNet보다 성능을 크게 향상시킴- 하지만 layer를 깊게 쌓으면 어느 순간부터 학습이 잘 되지 않고 train error가 높아짐 (overfitting 문제 X)
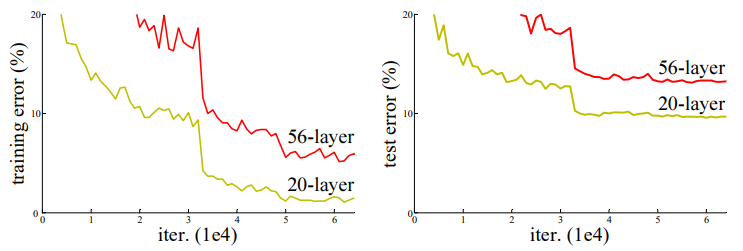
- residual learning을 통해 문제를 해결
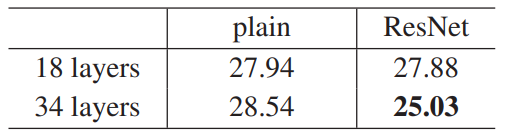
- 성능이 전반적으로 향상되었고 깊은 네트워크가 더 좋은 성능을 보임
VGGNet보다 8배 깊지만 complexity는 더 낮음
모델 구조
- 이전 레이어의 output x를 보존하고 추가적인 residual 정보를 함께 학습하는 방식으로, 최적화가 용이하다는 장점이 있음
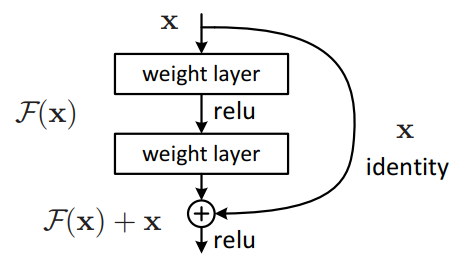
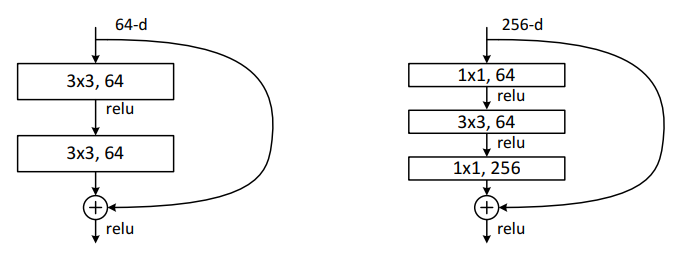
FC layer사용하지 않음Dropout사용하지 않음Batch Normalization사용- ResNet50 이상의 깊은 네트워크에는 효율성 향상을 위해 bottle neck 구조를 사용함 (
GoogLeNet의 Inception module과 유사) 1x1 conv를 거쳐 feature map의 depth를 줄임으로써(28x28x256 $\rightarrow$ 28x28x64) 3x3 conv에 필요한 계산량을 줄임
배치 정규화(Batch Normalization)
배치 정규화 등장 이전
- 입력 정규화(Normalization)
- 입력 데이터를 각각의 feature(축)에 대해서 0~1 범위 내의 값으로 정규화하는 것
- 원본 데이터를 그대로 사용하는 것보다 상대적으로 더 큰 learning rate를 사용할 수 있기 때문에 학습 속도가 더 빨라짐
- 입력 표준화(Standardization)
- 입력 데이터를 각각의 feature(축)에 대해서 N(0,1) 정규분포를 따르도록 표준화하는 것
- 화이트닝
- 입력 데이터를 평균이 0이고 공분산이 단위행렬인 정규분포 형태로 변환하는 것
입력 데이터 자체를 변환하는 방법의 한계점
- 입력 데이터를 정규화/표준화하더라도, hidden layer를 거치면서 연구자가 예상할 수 없는 방향으로 분포가 변화할 수 있음
- Internal Covariate Shift(ICS): the change in the distribution of layer inputs caused by updates to the preceding layers
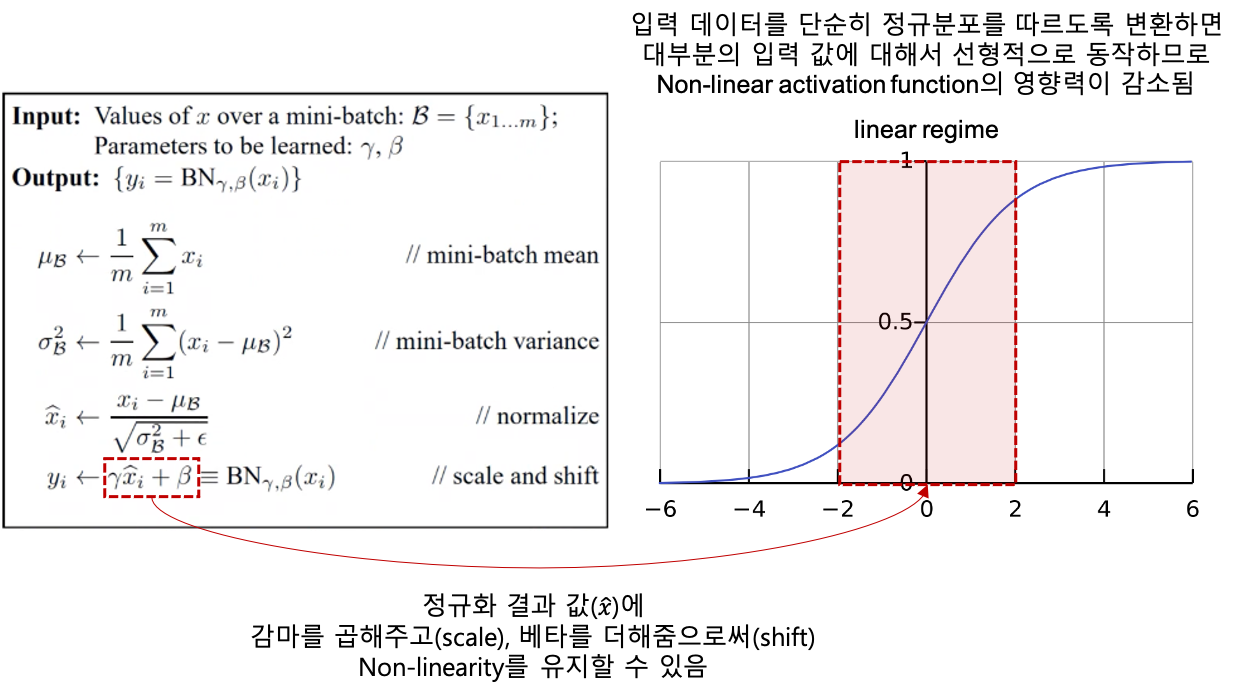
배치 정규화의 계산 과정
- 실제로 학습되는 파라미터는 감마와 베타
- hidden layer의 입력 차원이 $k$이면 $2k$개의 파라미터를 학습하는 것
배치 정규화의 장점
- 입력 데이터의 분포를 안정적으로 고정(ICS 감소) > optimizer가 saturated regime에 빠지지 않도록 하여 학습 속도를 개선
- 배치 정규화가 ICS를 확실히 감소시키는지에 대해서는 이견이 있음
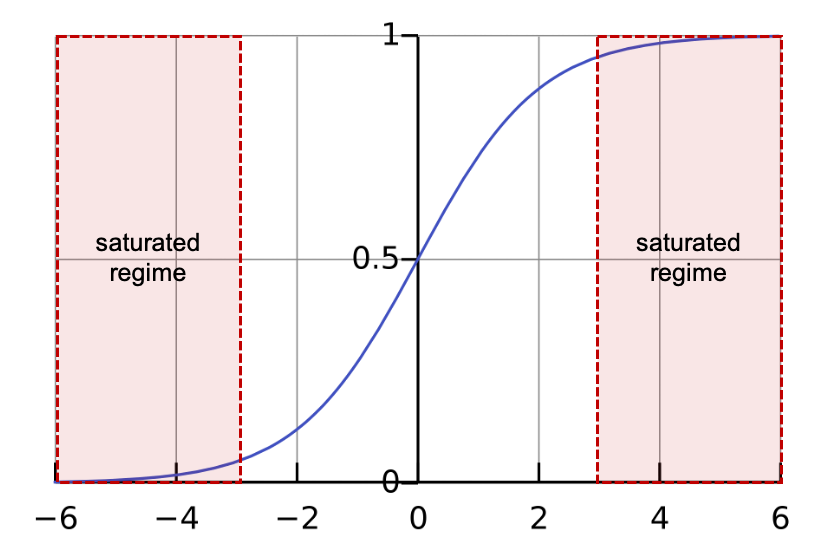
- 덜 정교한 하이퍼파라미터 세팅에도 대체로 잘 수렴함 > 가중치 초기화에 대한 민감도 감소
- 일반화 효과
- Smoothing 효과로 인한 성능 향상
- gradient, loss의 변동폭이 크면 gradient의 방향성을 신뢰하기 어렵고, optimization도 어려움 (안정적인 학습 어려움)
- 립시츠 연속 함수
- 연속적이고 미분 가능하며 어떠한 두 점을 잡아도 기울기가 $K$보다 작은 함수
- 급격한 변화 없이 ($K$만큼) 전반적으로 완만한 기울기를 가지는 형태의 함수
- 파라미터에 대한 목적함수가 립시츠 연속이면 안정적인 학습이 가능하다는 의미
- 현재의 gradient 방향으로 큰 스텝만큼 이동해도 이동하기 전과 방향이 유사할 가능성이 높음 = 큰 learning rate를 사용해도 안정적인 학습 가능
주요 실험 결과
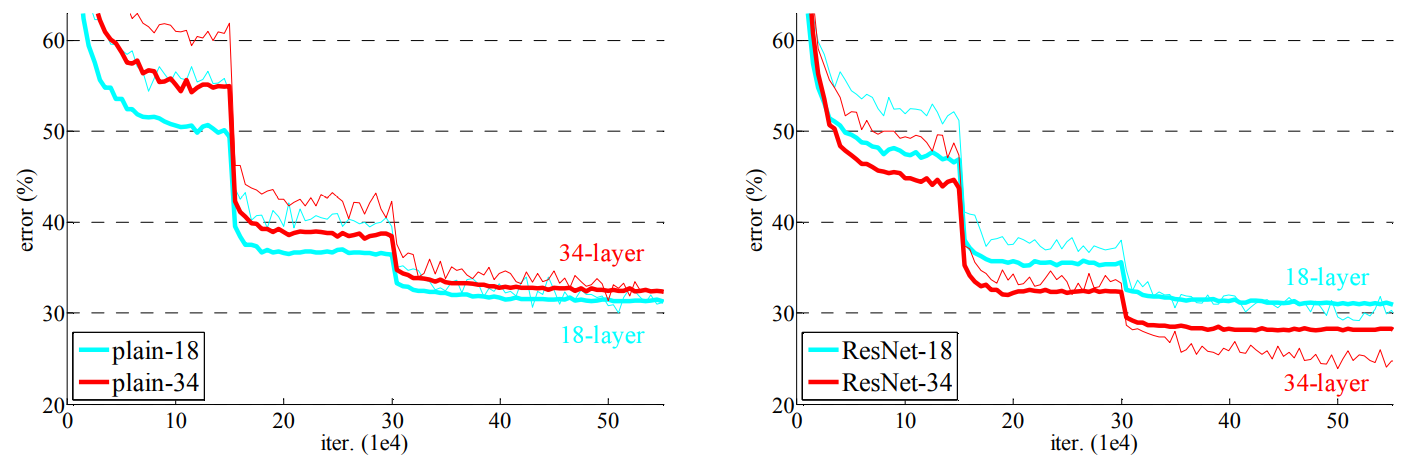
- plain net의 경우 layer를 깊게 쌓으면 에러율이 상승하지만, ResNet은 레이어를 깊게 쌓았을 때 에러율이 감소 (degradation 문제 해결)
- plain-34와 ResNet-34를 비교했을 때, training error가 감소
- plain-18과 비교해서 ResNet-18이 더 빠르게 수렴
Residual block 구현
- CONV-BN-ReLU
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35
class BasicBlock(tf.keras.layers.Layer): def __init__(self, filter_num, stride=1): super(BasicBlock, self).__init__() self.conv1 = tf.keras.layers.Conv2D(filters=filter_num, kernel_size=(3, 3), strides=stride, padding="same") self.bn1 = tf.keras.layers.BatchNormalization() self.conv2 = tf.keras.layers.Conv2D(filters=filter_num, kernel_size=(3, 3), strides=1, padding="same") self.bn2 = tf.keras.layers.BatchNormalization() if stride != 1: self.downsample = tf.keras.Sequential() self.downsample.add(tf.keras.layers.Conv2D(filters=filter_num, kernel_size=(1, 1), strides=stride)) self.downsample.add(tf.keras.layers.BatchNormalization()) else: self.downsample = lambda x: x def call(self, inputs, training=None, **kwargs): residual = self.downsample(inputs) x = self.conv1(inputs) x = self.bn1(x, training=training) x = tf.nn.relu(x) x = self.conv2(x) x = self.bn2(x, training=training) output = tf.nn.relu(tf.keras.layers.add([residual, x])) return output
ResNet 기반 모델
Wide ResNet (2017)
ResNet의 저자들은 layer를 깊게 쌓기 위해 filter 개수를 줄여 모델을 최대한 얇게 구성함Wide ResNet의 저자들은 실험을 통해 layer 개수(depth)를 늘리는 것보다 filter 개수(width)를 늘리는 것이 효과적이라고 주장 아래 표에서 $k$를 증가시키는 것이 모델을 wide하게 만드는 것
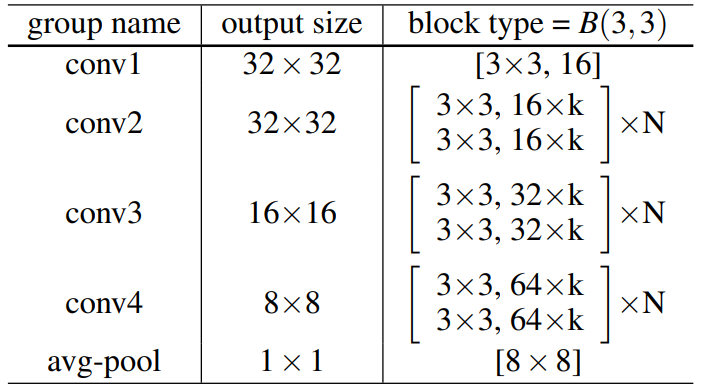
- convolutional layer들 사이에
Dropout추가
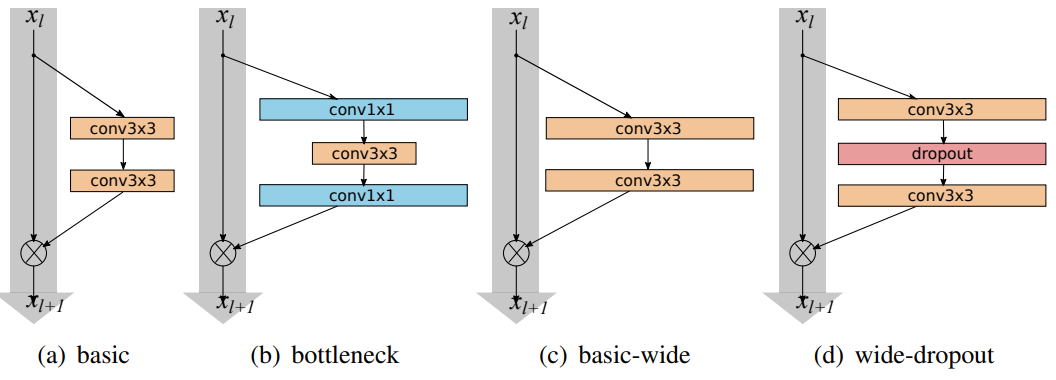
ResNext (2017)
- 과거에
Alexnet은 하드웨어 성능의 한계로 channel을 2개로 나누어 각기 다른 GPU로 학습했는데, 결과적으로 서로 다른 특징에 집중하여 학습할 수 있게 되면서 성능이 향상 되었음

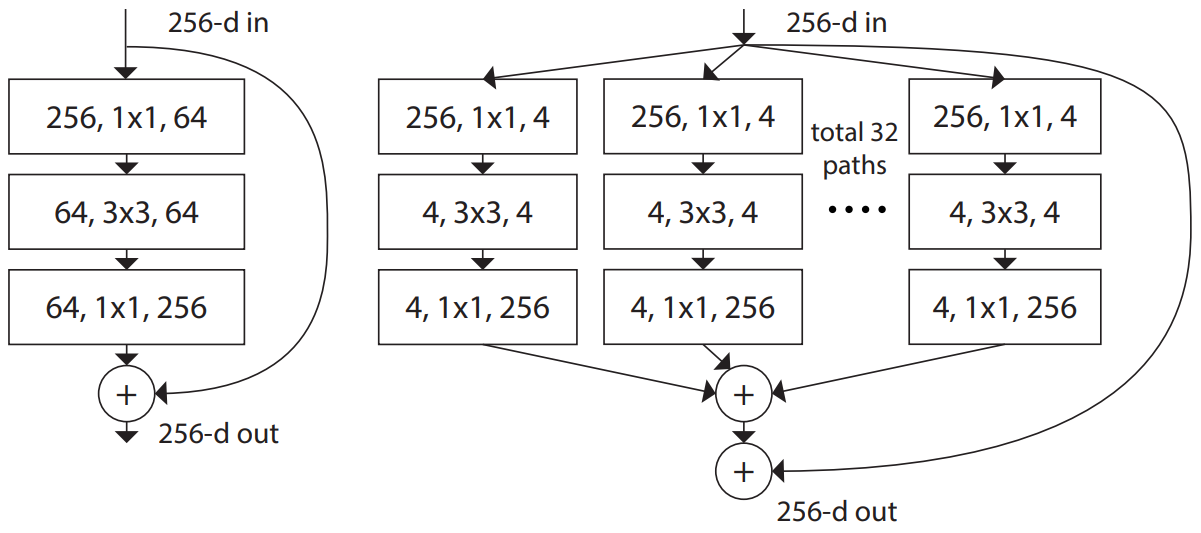
ResNext에서는ResNet도 channel을 여러 개의 그룹으로 분할하여 학습(group convolution)하면 성능이 향상 됨을 밝히고, network의 depth, width를 늘리는 것보다 cardinality를 늘리는 것이 성능 향상에 더 효과적임을 밝힘ResNet과 파라미터 수, 연산량은 비슷하지만 정확도가 더 높음- 예를 들어,
ResNet에서 크기가 1x1인 filter 64개를 거쳤던 과정(왼쪽)을 ResNext에서는 32개의 path로 나누어서 각 path마다 크기가 1x1인 filter 4개를 거치도록 함(오른쪽)
This post is licensed under CC BY 4.0 by the author.