[Paper Review] Qwen 2.5
Qwen은 알리바바 클라우드에서 개발한 LLM으로, 코딩과 수학적 추론 능력이 뛰어난 모델입니다.
1. 학습 데이터
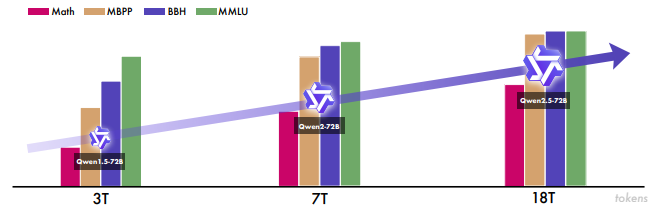
Pre-training 데이터셋을 기존(Qwen 2) 7조 토큰에서 18조 토큰으로 늘렸는데요. 지식, 코딩, 수학 영역을 중점적으로 보강했습니다.
2. 모델 구조
Qwen 2.5는 Dense Transformer를 사용하는 모델들과 MoE Transformer를 사용하는 Qwen2.5-Turbo, Qwen2.5-Plus 모델로 나뉩니다. Qwen2.5-Turbo와 Qwen2.5-Plus 모델은 Qwen 팀에서 제공하는 독점 모델로, 모델 구조나 weight 파일이 공개되지 않았습니다.
Dense Transformer를 사용하는 모델은 작은 규모(0.5B)부터 큰 규모(72B)까지 다양한 크기로 공개되었습니다. 이 중 Qwen 2.5-3B와 Qwen 2.5-72B를 제외하고 Apache 2.0 라이센스에 해당하는 나머지 모델들은 상업적으로도 사용이 가능합니다.

2.1 MoE Transformer
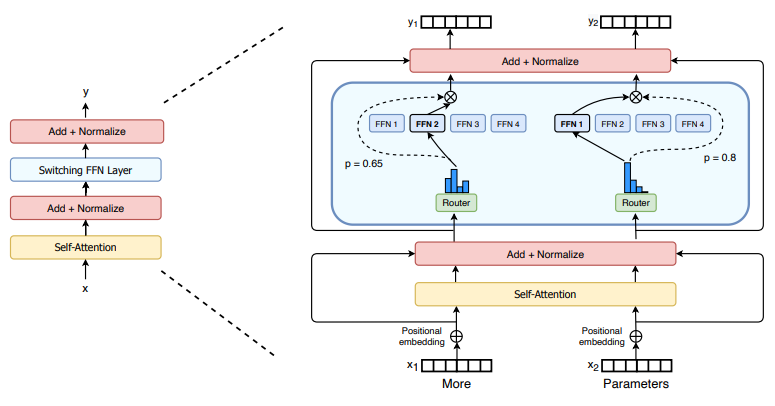 Switch Transformer
Switch Transformer
Fedus et al. (2021)은 Mixture of Experts(MoE) 개념을 Transformer 구조에 적용하여 LLM을 효율적으로 확장하는 방법을 제안했습니다. 여기에서 제안된 모델이 Transformer의 feed-forward network(FFN)를 MoE layer로 교체하여 만든 Switch Transformer입니다. 이 MoE layer는여러 개의 전문가(expert)와 각 토큰 $x$에 가장 적합하다고 판단되는 1개의 전문가를 할당하는 라우팅 메커니즘으로 구성됩니다. 위 그림은 4개의 전문가가 존재하는 케이스를 표현한 것입니다. 이렇게 하면 전체 파라미터를 항상 사용하지 않고 필요한 부분만 활성화하여 계산 비용을 절감하면서도 강력한 성능을 유지할 수 있습니다.
Qwen2.5-Turbo, Qwen2.5-Plus 모델도 이러한 MoE Transformer를 사용했습니다. 하지만 Switch Transformer처럼 1개의 전문가만 사용하는 것이 아니라, 2~4개의 전문가를 선택하여 더 넓은 범위의 지식을 활용하면서도 계산 비용을 효율적으로 유지합니다. Dense Transformer는 MoE layer를 사용하지 않고, 기본적인 decoder-only Transformer를 사용해서 모든 토큰이 같은 파라미터를 쓰는 모델을 가리킵니다. 지난 포스트에서 다룬 Llama 3나 GPT 3도 Dense Transformer를 사용한 모델입니다.
2.2 Post-Training
Supervised Fine-Tuning (SFT)
Qwen 2.5는 Post-training의 첫 단계로 100만 개 이상의 샘플을 사용한 SFT를 수행합니다. 이 단계는 모델이 다양한 지시사항을 정확하게 이해하고 따르도록 학습시킵니다. 특히, Agent가 생성한 대규모 지시 데이터셋을 활용하여 긴 지시사항에 대한 데이터 부족 문제를 해결합니다.
Reinforcement Learning (RL)
SFT 이후에는 다단계 강화학습을 적용하여 모델이 사용자의 지시를 더 잘 이해하고, 사람의 선호에 맞는 답변을 생성하도록 했습니다.
- DPO (Direct Preference Optimization): 오프라인 학습 기술로, 사람의 선호가 반영된 질문-응답 쌍같은 고정 데이터를 사용해 정책을 직접 최적화하는 방식입니다. 기준 정책 $\pi_{\mathrm{ref}}$ 대비 선호 응답 $y^+$과 비선호 응답 $y^-$의 로그확률 차이가 커지도록 최적화합니다.
- GRPO (Group Relative Policy Optimization): 온라인 학습 기술로, 모델이 생성한 여러 응답의 평균을 기준선으로 보상을 상대화해서 정책을 업데이트합니다.
Llama 시리즈와 Qwen의 모델 정보를 비교해 보면 아래와 같습니다.
| 구분 | Llama 3 | Llama 3.1 | Qwen 2.5 (Dense) | Qwen 2.5 (MoE) |
|---|---|---|---|---|
| 모델 구조 | Dense Transformer | Dense Transformer | Dense Transformer | MoE Transformer |
| Attention | GQA | GQA | GQA | GQA |
| Activation Function | SwiGLU | SwiGLU | SwiGLU | SwiGLU |
| Positional Embedding | RoPE | RoPE | RoPE | RoPE |
| 정규화 | RMSNorm | RMSNorm | RMSNorm | RMSNorm |
| pre-training 데이터셋 규모 (토큰) | 15조 | 15조 | 18조 | 18조 |
| 모델 크기 | 8B, 70B | 8B, 70B, 405B | 0.5B ~ 72B | Turbo, Plus |
| Context Window | 8K | 128K | 128K | 1M |
| Post-Training | SFT → Rejection Sampling → DPO | SFT → Rejection Sampling → DPO | SFT → DPO → GRPO | SFT → DPO → GRPO |
3. 모델 성능
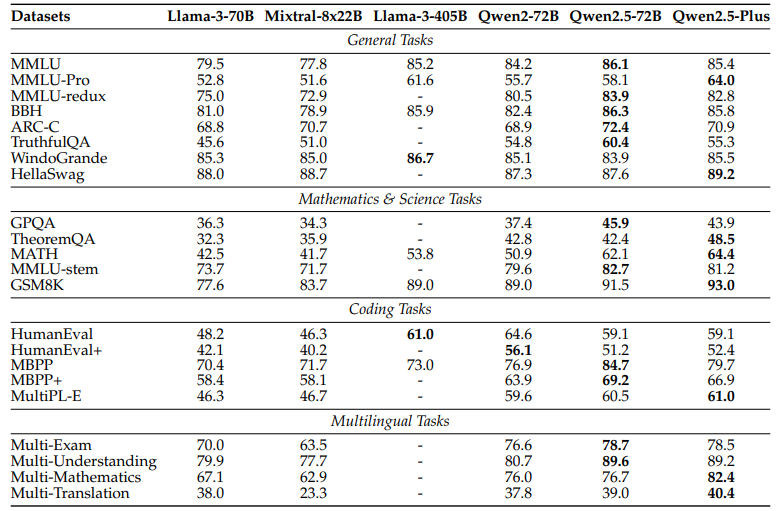
위 표는 Qwen2.5-Plus 모델과 70B 이상의 대규모 오픈소스 모델들의 성능을 비교한 것입니다. 이 표의 핵심은 Qwen2.5-Plus가 MoE 구조를 사용하여 활성화 되는 파라미터 수가 훨씬 적음에도 불구하고, 경쟁 모델들과 대등하거나 더 우수한 성능을 보여준다는 점입니다.
Reference
- LLM 아키텍처에 Mixture of Experts(MoE)를 활용하기
- Mixture-of-Experts with Expert Choice Routing
- Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity