대표적인 머신러닝 학습 방법 4가지
이번 포스트에서는 대표적인 머신러닝 학습 방법인 Supervised Learning, Unsupervised Learning, Self-Supervised Learning, Semi-Supervised Learning에 대해 정리해보겠습니다.
1. Supervised Learning
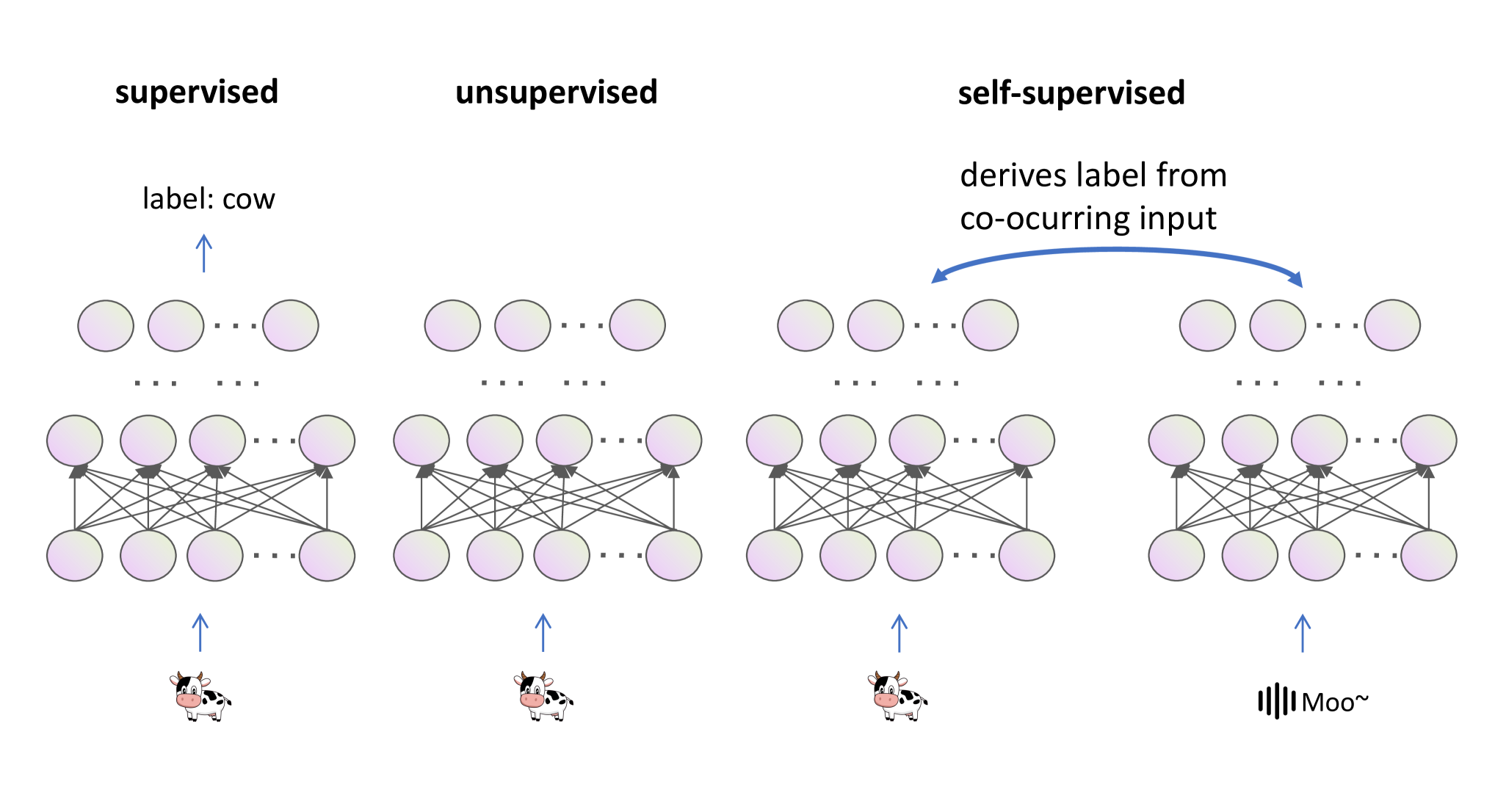
Supervised learning은 많은 분들에게 가장 익숙한 방식일 것입니다. 사람이 데이터에 붙인 라벨을 정답으로 삼아 학습하는 방식입니다. 위 그림에서는 소 이미지를 cow라는 label로 분류하는 모델을 보여주고 있습니다. 직관적인 방식이지만 라벨링 작업이 필수적이기 때문에 데이터셋이 커질수록 많은 시간과 비용이 소요된다는 단점이 있습니다.
2. Unsupervised Learning
Unsupervised learning은 라벨이 따로 존재하지 않고, 데이터의 구조나 패턴을 학습합니다. 각 데이터 샘플을 $k$개의 중심점에 할당해 비슷한 데이터끼리 묶는 k-means 클러스터링이나 데이터의 핵심 패턴을 추출해 차원을 축소하는 기법인 PCA가 여기에 속합니다. 라벨링은 필요하지 않지만 데이터 구조만 파악해서 실제 예측 성능으로 이어지기가 어렵다는 한계가 있습니다.
3. Semi-supervised Learning
Semi-supervised learning은 전체 데이터 중에서 일부만 라벨링하는 방식입니다. 다양한 구현 방식이 있지만, 대표적인 예를 들어보면 아래와 같습니다.
- 소량의 라벨 데이터로 초기 모델을 학습합니다.
- 1번의 모델로 라벨이 없는 데이터에 임시 라벨(pseudo label)을 부여합니다.
- 초기 라벨과 임시 라벨을을 합쳐서 다시 모델을 학습합니다.
- 위 과정을 반복합니다.
초기 모델을 학습할 만큼의, 적은 양의 라벨만 필요하므로 Supervised learning 보다 라벨링에 훨씬 적은 시간과 비용이 소요되고, 동시에 Unsupervised learning 보다 좋은 성능을 기대할 수 있습니다. 하지만 초기 라벨의 품질이 낮으면 모델 정확도가 낮아지기 때문에 오류가 점차 증폭될 위험이 있습니다.
4. Self-supervised learning
Self-supervised learning은 데이터 자체로부터 파생된 가짜 라벨(proxy label)을 예측해 데이터 embedding을 학습합니다. 위 그림의 Self-supervised learning에서 소 이미지와 소 울음소리는 Supervised learning처럼 명시적으로 라벨링되어 있지 않습니다. 대신, 두 데이터가 동시에 등장한다는 사실이 암묵적으로 proxy label 역할을 하게 됩니다.
대표적인 LLM 모델 중 하나인 BERT도 문맥 이해도를 높이기 위해 Self-supervised learning을 사용했는데요. BERT를 pretrain할 때 수행한 두 가지의 task인 Masked Language Learning(MLM)과 Next Sentence Prediciton(NSP)입니다. MLM은 주어진 문장의 일부 토큰을 [MASK]로 대체해서 가리고 모델이 마스킹된 토큰을 예측하는 task입니다. proxy label로 사용할 15%의 토큰을 랜덤하게 골라서 [MASK] 토큰으로 바꿔주기만 하면 되기 때문에 별도의 라벨링 작업이 필요하지 않습니다.
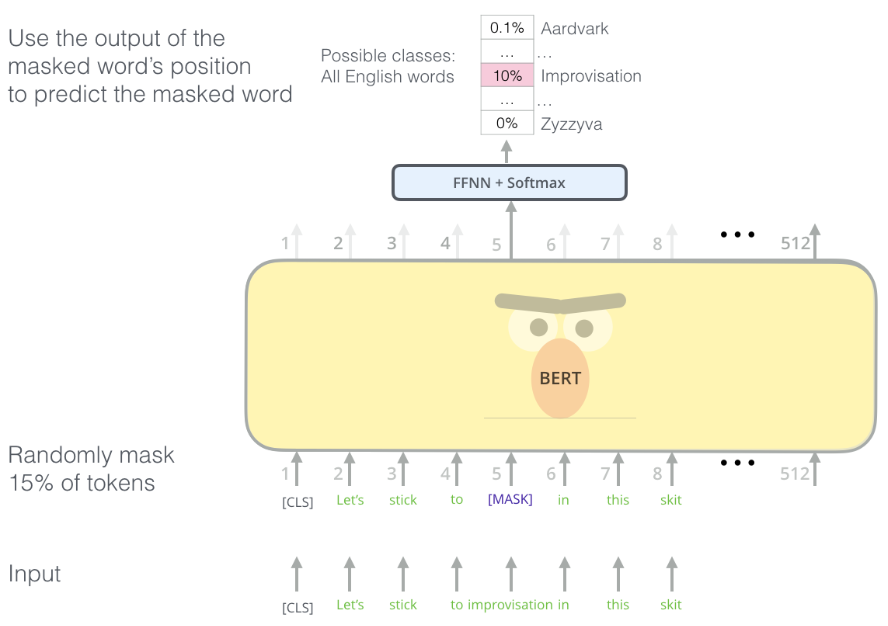 Masked Language Learning
Masked Language Learning
다음으로 NSP는 주어진 두 개의 문장이 이어지는 문장인지 아닌지 맞추는 task입니다. 절반은 실제로 이어지는 두 문장을, 나머지 절반은 랜덤하게 골라 데이터셋을 만들어 학습을 진행합니다. 이 역시 라벨링이 필요하지 않은 task입니다.
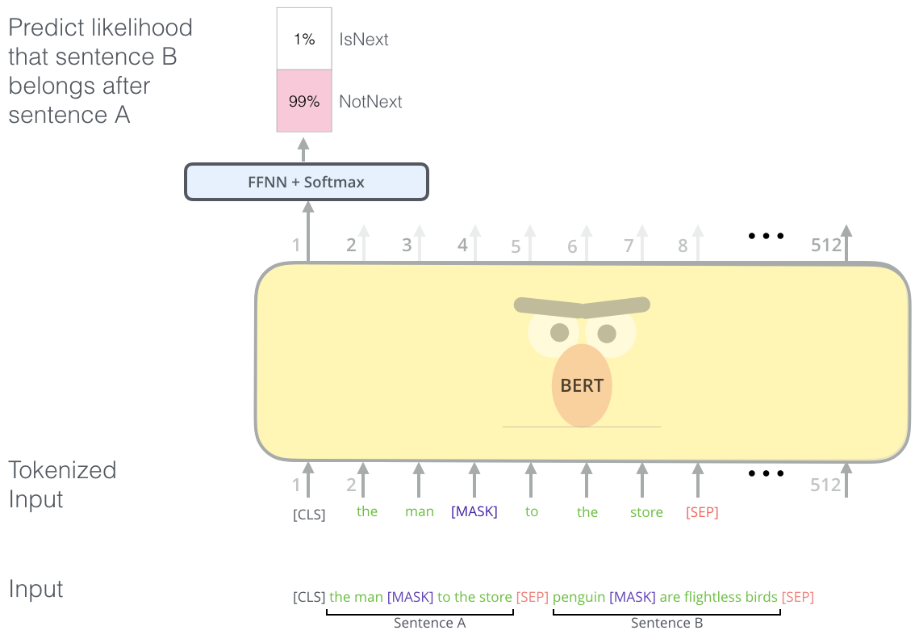 Next Sentence Prediciton
Next Sentence Prediciton
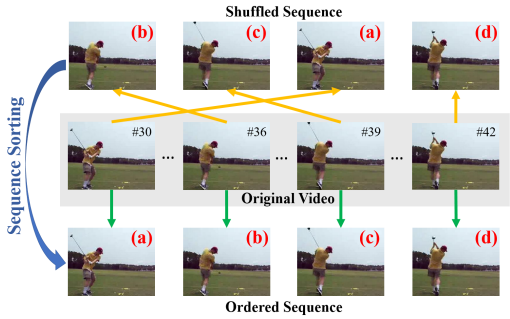
Vision 분야에서는 주어진 비디오나 이미지를 원본과 다르게 변형해서 proxy label을 만듭니다. 아래 예시에서는 비디오에서 임의로 4장의 프레임을 뽑아 순서를 뒤섞은 다음, 모델이 올바른 순서로 재배열하도록 학습합니다. 원래 순서가 곧 정답 순서이기 때문에 별도의 라벨링없이 학습할 수 있습니다.
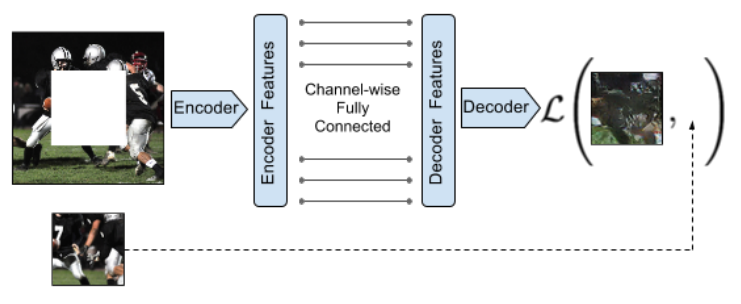
아래 예시에서는 모델이 이미지의 가려진 영역을 복원하는 task를 수행합니다. 모델이 복원한 이미지와 원본 이미지와의 차이를 계산해 loss로 사용합니다. 라벨로 사용되는 원본 이미지는 이미 가지고 있기 때문에 라벨링이 필요하지 않습니다.
마지막으로 위 예시들과는 조금 다르게, 데이터 간의 유사성과 차이점을 학습해 embedding을 만드는 Contrastive learning이 있습니다. Contrastive learning은 의미적으로 유사한 데이터 쌍인 positive pair와 그렇지 않은 negative pair를 정의합니다. 예를 들어, 서두의 이미지에서 소 이미지와 소 울음소리는 positive pair입니다. 또는 원본 이미지에 서로 다른 augmentation을 수행해 positive pair를 만드는 방식을 사용할 수 있습니다. 그 다음, positive pair의 embedding은 서로 가깝게, 반대로 negative pair의 embedding은 멀어지도록 모델을 학습시켜 데이터의 embedding을 만듭니다. Contrastive learning의 대표 모델 중 하나인 SimCLR에 대해서는 다음 포스트에서 다뤄보도록 하겠습니다.