[Paper Review] Llama 3
Llama 2의 후속 모델인 Llama 3는 모델 구조 자체는 Llama 2와 동일하지만, post-training 시에 Llama 2와 조금 다른 과정을 거칩니다. post-training은 Llama 시리즈에서 뿐만 아니라 최근 발표되는 LLM 논문에서 자주 등장하는 용어인데요. 단순히 fine-tuning 하나의 기술만 의미하는 것이 아니라, 다음을 포함하는 여러 단계와 기법들을 아우르는 개념입니다.
- Supervised Fine-Tuning (SFT): 100만 개 이상의 고품질 데이터셋을 사용하여 모델이 특정 지시(instruction)를 따르도록 학습시키는 단계입니다.
- 보상 모델: 사람의 선호도를 학습하여, 모델의 답변에 점수를 부여하는 보상 모델(Reward Model)을 만드는 단계입니다.
- 강화 학습: SFT와 보상 모델을 바탕으로, 모델이 더 좋은 답변을 생성하도록 훈련하는 단계입니다. 이 단계에는 PPO, DPO, GRPO 등 다양한 기술이 포함되며, Llama 3에서는 PPO와 DPO를 결합해서 사용합니다.
- 안전성 및 윤리 정렬: 유해하거나 편향된 답변을 생성하지 않고, 인간의 가치와 의도에 부합하도록 모델을 훈련하는 과정입니다.
본 포스트에서는 Llama 2와 비교해서 post-training에 어떤 변화가 있었고, 결과적으로 어느 정도의 성능 향상이 있었는지를 중점적으로 다뤄보겠습니다.
1. 학습 데이터
Llama 3에서는 Llama 2보다 데이터의 양과 질을 크게 향상시켜 사용했는데요. Llama 2에서 pre-training에 약 1.8조 개의 토큰을 사용한 것과 비교해, Llama 3에서는 약 15조 개의 다국어 토큰을 사용했습니다. 토큰 개수를 8개 가량 증가시킨 것입니다. 또한, 섬세한 전처리 과정을 거친 데이터를 pre-training에 사용하고, 엄격한 기준으로 필터링한 데이터로 post-training을 진행했습니다.
Tokenizer는 이전 Llama 시리즈들과 동일하게 bytepair encoding (BPE) 알고리즘을 사용했지만, vocabulary size를 32,000에서 128,256으로 대폭 증가시켰습니다. 이처럼 vocabulary size가 커지면 동일한 문장을 표현하는 데 필요한 토큰 수가 줄어들어 모델 효율성이 향상됩니다. 예를 들어, vocabulary 집합에 “transformer”라는 단어가 없다면 Tokenizer는 “transformer”를 “trans-“, “-former”와 같이 여러 개의 작은 단위로 쪼개야 합니다. 하지만 vocabulary 집합에 다양한 단어들을 포함시키면 텍스트를 인코딩할 때 더 큰 단위로 묶을 수 있어서 토큰의 전체 수가 줄어듭니다. “transformer”를 1개의 토큰만으로 표현할 수 있는 것입니다.
2. 모델 버전별 차이
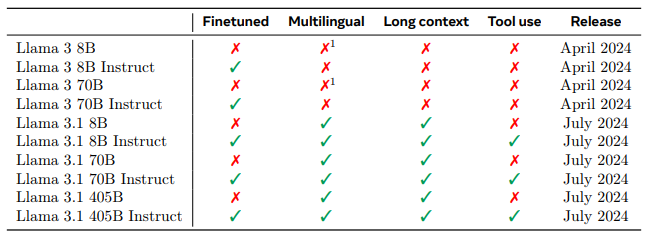
Llama 3 시리즈는 크게 초기 모델에 속하는 Llama 3와 Llama 3.1 이후로 나누어 볼 수 있습니다. Llama 3는 8B, 70B 두 가지 크기로 출시되었습니다. 다국어 데이터로 pre-training을 거친 모델이긴 하지만, 영어 최적화를 목표로 개발되어서 비영어권 언어 성능이 다소 떨어집니다. 그리고 context length가 8K로 짧은 수준이고, tool 사용이 불가능하다는 한계점이 있습니다. 여기에서 tool 사용이란 LLM이 내부 지식만으로 해결할 수 없는 작업을 외부의 특정 도구를 호출하여 해결하는 능력을 말합니다. 예를 들어, “내일 서울 날씨는 어때?”와 같은 질문에 답하기 위해 실시간 날씨 정보를 얻을 수 있는 날씨 API를 호출하는 것입니다.
후속 모델인 Llama 3.1부터는 405B 크기의 모델이 추가되었습니다. 다국어 성능이 향상되고, context length도 128K로 크게 증가했습니다. Llama 1과 Llama 2의 context length가 각각 2K와 4K임을 상기해보면, 불과 1년 남짓 사이에 context length가 64배 증가한 것입니다. 또한 tool 사용도 가능해 졌습니다.
3. 모델 구조
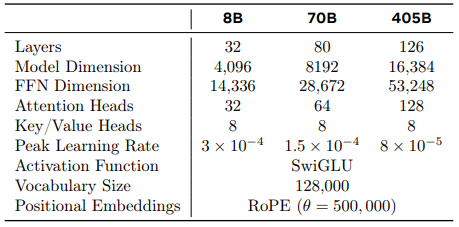
앞서 설명한 것처럼, Llama 3의 모델 구조 자체는 Llama 2와 동일합니다. Llama 시리즈는 Llama 1부터 Llama 2, 그리고 Llama 3에 이르기까지 다음과 같은 핵심적인 구조를 공유하고 있습니다.
grouped-query attention (GQA): Llama 2에서부터 사용되기 시작한 attention 구조입니다. Query를 여러 그룹으로 나누고 그룹별로 Key, Value를 공유해서 메모리와 연산량을 크게 절약할 수 있습니다.Pre-normalization: Transformer block의 각 sub-layer에 들어가는 input을 정규화하는 구조입니다.RMSNorm: Pre-normalization에 사용되는 정규화 알고리즘으로, 계산 효율성이 뛰어납니다.SwiGLU: 기존의 ReLU보다 더 복잡하고 유연한 표현이 가능한 activation function입니다.Rotary Positional Embeddings (RoPE): 토큰의 위치에 따라 embedding vector를 일정 각도로 회전시켜서 순서 정보를 입력하는 방식으로, 긴 시퀀스 처리에 유리합니다.
Post-Training
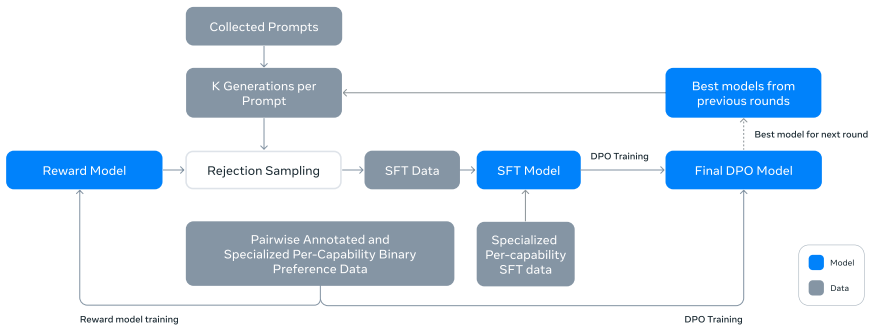
Llama 3의 post-training 과정은 SFT, Rejection Sampling과 DPO로 나눌 수 있습니다. 이 과정을 여러 번 반복하여 모델의 성능을 점진적으로 개선하였습니다.
Reward Modeling
Llama 2가 유용성과 안전성을 위한 두 개의 보상 모델을 사용했던 것과 달리, Llama 3는 여러 능력을 종합적으로 평가하는 하나의 단일 보상 모델을 사용했습니다. 이 보상 모델은 유용성, 안전성, 지시 준수 등 다양한 기준을 동시에 평가하도록 학습되었습니다.
SFT와 Rejection Sampling
Llama 2처럼 Llama 3에서도 Rejection Sampling을 사용합니다. Rejection Sampling은 보상 모델이 평가한 여러 응답 후보 중 가장 높은 점수를 받은 응답만 선별하는 것입니다. 이렇게 선별된 데이터셋으로 SFT을 진행했습니다. 이를 통해 SFT 단계부터 모델이 보상 모델이 선호하는 응답 패턴을 학습하게 됩니다.
DPO (Direct Preference Optimization)
Llama 2에서 PPO를 사용했던 것과 달리, Llama 3에서는 DPO를 사용합니다. DPO는 사람의 선호가 반영된 질문-응답 쌍같은 고정 데이터를 사용해 정책을 직접 최적화하는 오프라인 방식입니다. 별도의 보상 모델을 학습시키지 않지만, 데이터셋 자체에 이미 인간의 선호도가 반영되어 있기 때문에 사실상 보상 모델이 수행하는 역할을 데이터셋이 대신하는 것으로 볼 수 있습니다. 아래와 같이 기준 정책 $\pi_{\mathrm{ref}}$ 대비 선호 응답 $y^+$과 비선호 응답 $y^-$의 로그확률 차이가 커지도록 최적화합니다.
\[\mathcal{L}_{\mathrm{DPO}}(\theta) = -\mathbb{E}\!\left[ \log \sigma\!\left( \beta\!\left( \log \frac{\pi_\theta(y^{+}\mid x)}{\pi_{\mathrm{ref}}(y^{+}\mid x)} - \log \frac{\pi_\theta(y^{-}\mid x)}{\pi_{\mathrm{ref}}(y^{-}\mid x)} \right)\right)\right]\]4. 모델 성능
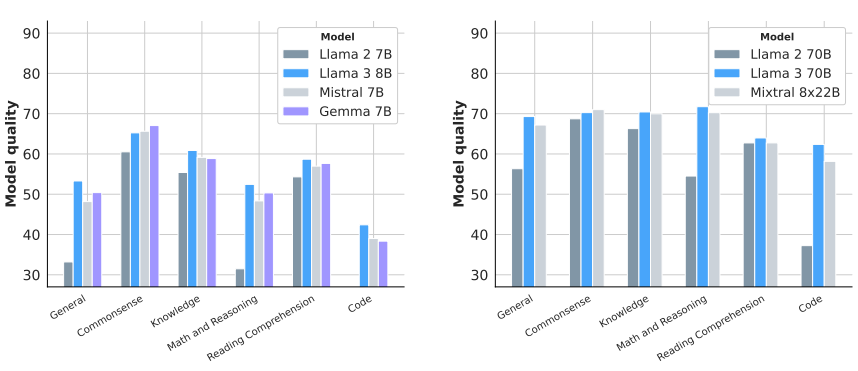
위 그래프에서 알 수 있듯이, Llama 3가 비슷한 크기의 다른 모델들보다 대부분의 영역에서 최고 성능을 보였습니다. 특히, Llama 2와 비교했을 때 수학과 추론, 코딩 능력에서 비약적인 성능 상승이 있었습니다.
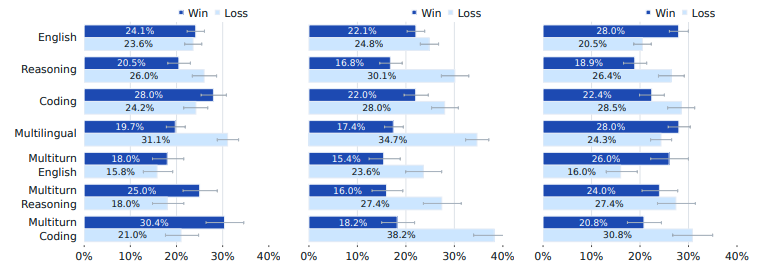
위 그래프는 Llama 3 405B와 GPT-4 (좌측), GPT-4o (가운데), 그리고 Claude 3.5 Sonnet (우측)의 성능을 사람이 직접 평가한 결과입니다. Llama 3 405B는 GPT-4o보다는 모든 영역에서 성능이 낮았지만, GPT-4와는 비슷한 성능을 보였습니다. 특히 Multiturn 성능이 높게 나타났는데, 이는 Llama 3가 이전 대화 맥락을 파악하고 일관성을 유지하는 능력이 뛰어나다는 것을 의미합니다. 하지만 다국어와 추론 능력에서는 GPT-4보다 낮은 성능을 보였습니다.
Claude 3.5 Sonnet과 비교했을 때는 코딩과 추론 능력에서 Llama 3가 더 낮은 성능을 보였습니다. 반면, 다국어나 영어 능력에서는 성능이 더 높았습니다. Llama 3는 다수의 영역에서 최신 상용 모델들과 동등하거나 혹은 더 우수한 성능을 보이면서, 오픈 소스로 공개된 모델이라는 점에서 큰 의의를 갖습니다.