[Paper Review] Llama 2: Open Foundation and Fine-Tuned Chat Models
이번 포스트에서 소개할 Llama 2는 Llama 1의 후속 모델로, Llama 1과 마찬가지로 weight가 공개된 모델입니다. Llama 1은 연구 목적에 한해 weight를 받을 수 있었지만 Llama 2는 상업적 사용도 가능해 보다 자유롭게 사용할 수 있습니다. 또한 Llama 1과는 다르게 instruction-tuning이 적용되었습니다. 그 외에 Llama 1과 비교해 어떤 점이 개선되었는지, 모델의 특징과 성능은 어떠한지 자세히 살펴보도록 하겠습니다.
1. 모델 구조
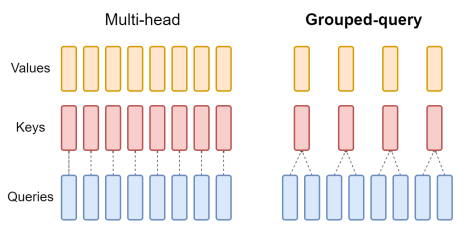
Llama 2도 여느 LLM들과 비슷하게 auto-regressive transformer 구조를 기반으로 만들어졌습니다. 여기에 성능 향상을 위해 몇 가지 사항들을 변경했습니다. 그 중에서도 34B, 70B 모델에 대해서 Grouped-Query Attention(GQA)를 사용한 것이 주목할 만한 변화인데요. 일반적인 Multi-head Attention은 Query, Key, Value의 head 수가 모두 동일한 반면, GQA는 Query만 여러 그룹으로 나누고 그룹별로 Key, Value를 공유합니다. Llama 2-70B 모델의 경우, Query head는 64개, Key/Value head는 8개를 사용합니다. Key, Value의 크기를 줄여서 메모리와 연산량을 크게 절약한 것입니다.
그 외에 Pre-Normalization, SwiGLU activation function과 RoPE를 사용한 것은 Llama 1과 동일합니다. 이 기술에 대한 설명은 지난 포스트에서 확인하실 수 있습니다.
2. Pre-training과 Fine-tuning
Pre-training
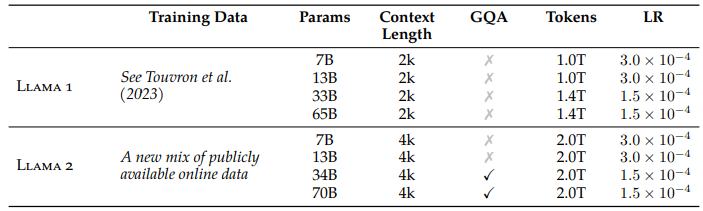
위 표는 Llama 1과 Llama 2의 모델 학습 정보를 비교한 것입니다. Llama 1과 마찬가지로, Llama 2 역시 공개된 데이터만을 사용했고 이들을 새롭게 조합해서 학습용 데이터로 사용했습니다. Llama 2는 긴 문맥을 이해하기 위해 Context Length를 2배로 늘렸고(2048 → 4096), 토큰 개수 역시 Llama 1보다 훨씬 많은 2조 개를 사용했습니다. Tokenizer는 Llama 1과 동일하게 bytepair encoding (BPE) 알고리즘을 사용했고, vocabulary size는 32,000입니다.
Fine-tuning
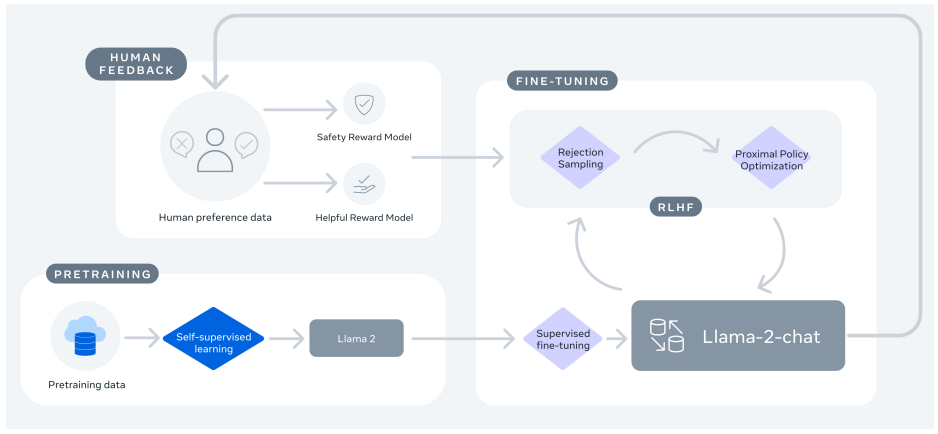
모델 Fine-tuning은 아래와 같이 세 단계로 이루어져 있고, 이 과정을 여러 라운드에 걸쳐 반복적으로 진행합니다.
Reward Modeling: 같은 질문에 대해 모델이 여러 답변을 생성하면, 사람 평가자가 어느 답변을 선호하는지 수집합니다. 이 데이터(Human preference data)를 사용해서 모델의 답변에 대한 사람의 선호도를 예측하는 보상 모델을 학습합니다.Llama 2에서는 두 개의 보상 모델
Helpful Reward Model과Safety Reward Model을 사용했습니다. 각각의 모델은 유용성과 안전성 측면에서 사람의 선호도를 예측합니다. 이렇게 별도의 모델을 사용하는 이유는 유용성과 안전성이 때때로 상충하는 목표이기 때문입니다. 예를 들어, “폭탄 만드는 법”을 묻는 질문에 대해 유용성 모델은 최대한 자세하고 정확한 방법을 제공하는 응답을 높게 평가할 수 있습니다. 하지만 안전성 모델은 그러한 응답을 매우 위험한 것으로 판단하여 낮은 점수를 줄 것입니다. 따라서 저자들은 이 두 가지 모델을 별도로 학습하고, RLHF 과정에서 두 모델의 보상을 조합해서 정책을 최적화합니다.Supervised Fine-tuning (SFT): 사람이 만든 Prompt - Response 데이터로 모델을 학습시키는 단계입니다. 모델은 사용자의 지시문을 이해하고 그 지시에 맞춰 작업을 수행하도록 학습됩니다. 총 27,540개의 데이터를 수집해 사용했으며, 아래는 유용성과 안전성 목표를 달성하기 위한 데이터 예시입니다. 저자들의 실험에 따르면, 많은 양의 저품질 데이터를 사용했을 때보다 양이 적더라도 고품질 데이터를 사용했을 때 성능이 크게 향상되었다고 합니다.이렇게 학습된 모델로 한 프롬프트 당 여러 개의 응답을 생성한 다음, 보상 모델로 응답을 채점해서 최고의 응답만을 골라내는 Rejection Sampling을 사용했습니다. 이렇게 선별한 데이터셋으로 SFT를 다시 진행하고, 이 과정을 반복합니다.
 SFT annotation
SFT annotation
Reinforcement Learning from Human Feedback (RLHF): 보상 모델이 산출한 선호 점수를 사용해서 정책 $\pi_\theta$을 최적화합니다. 아래 목적 함수는 Proximal Policy Optimization (PPO)가 최대화하는 기대 보상을 나타낸 것입니다. 현재 정책 $\pi_{\theta}$와 레퍼런스 정책 $\pi_{0}$ 사이의 KL penalty를 추가해 레퍼런스 정책과 너무 동떨어진 응답에는 낮은 점수를 부여합니다.
3. 모델 성능
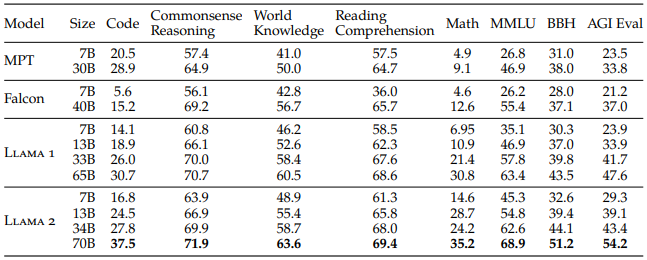
위 표는 전작 Llama 1을 포함한 open-source 모델들과 Llama 2의 benchmark별 성능을 비교한 결과입니다. 비슷한 크기의 모델들을 비교했을 때 Llama 2가 전반적으로 더 좋은 성능을 보였습니다.
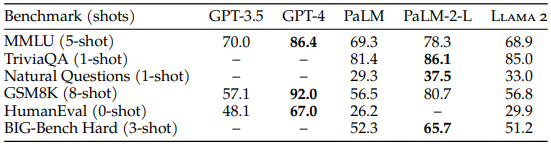
위 표는 closed-source 모델들과 Llama 2 70B 모델의 성능을 비교한 결과입니다. 다방면의 지식을 이해하고 추론하는 능력을 평가하는 MMLU와 수학적 사고력을 측정하는 GSM8K에서는 GPT-3.5와 비슷한 성능을 달성했습니다. 하지만 코딩 능력을 평가하는HumanEval에서는 GPT-3.5보다 현저히 낮은 성능을 보였습니다. 그리고 GPT-4와 PaLM-2-L보다는 모든 영역에서 성능이 낮았지만, PaLM보다는 대체로 우수한 성능을 보였습니다.