[Paper Review] DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
작년 9월, OpenAI에서 추론 모델 o1을 발표했습니다. OpenAI 연구팀은 o1 개발 과정에서 강화 학습을 늘리고(train-time compute) 생각을 더 오래 할수록(test-time compute) o1의 성능이 일관적으로 향상하는 것을 확인했습니다. 하지만 모델이 생각하는 시간을 무한정 늘릴 수는 없기 때문에 어떻게 하면 이 test-time을 효율적으로 사용할 것인지가 중요한 문제로 대두되었습니다.
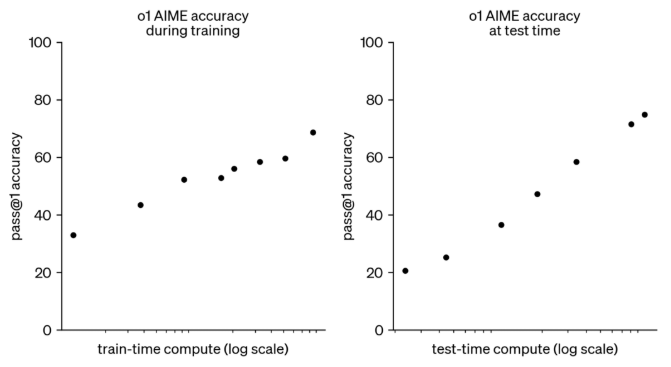
DeepSeek 연구팀은 이 문제를 강화 학습으로 풀고자 했습니다. 논문 제목에서도 알 수 있듯이 DeepSeek-R1은 강화 학습을 통해 추론 능력을 향상시킨 모델로, GPT-4o, Claude 3.5-Sonnet과 같은 최신 모델에 필적하는 성능을 달성했습니다. 게다가 이 고성능 모델의 weight를 공개해 학술적 연구뿐만 아니라 상업적 용도로 자유롭게 사용할 수 있도록 했다는 점에서 출시와 동시에 AI 업계에 큰 반향을 일으켰습니다. 이번 포스트에서는 DeepSeek-R1이 경쟁 모델들과 어떤 차이가 있고, 구체적으로 어느 정도의 성능을 달성한 것인지 자세히 살펴보겠습니다.
1. DeepSeek-V3 모델 구조
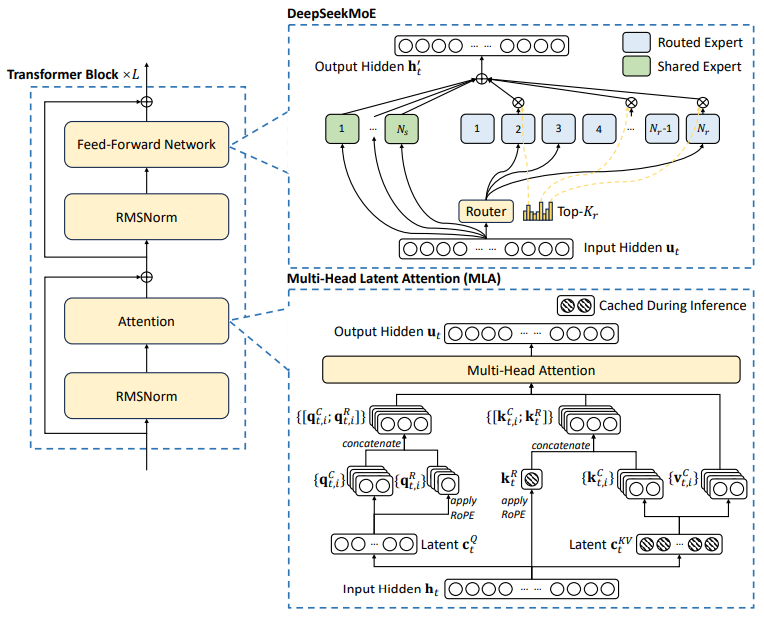
DeepSeek-R1은 작년에 발표된 DeepSeek-V3를 기반으로 강화 학습 Post-Training을 적용해 추론 능력을 한 층 끌어올린 모델입니다. DeepSeek-R1에 대해 알아보기에 앞서, 베이스 모델인 DeepSeek-V3의 모델 구조를 살펴보겠습니다. DeepSeek-V3 모델 구조에서 주목할 만한 점은 MoE Transformer와 MLA를 사용했다는 것입니다.
1.1 Mixture of Experts (MoE)
지난 포스트에서 설명했듯이, MoE Transformer를 사용하면 전체 파라미터를 항상 사용하는 것이 아니라 필요한 부분만 활성화하기 때문에 계산 비용을 절감하면서도 강력한 성능을 유지할 수 있습니다. DeepSeek-V3의 전체 파라미터 수는 6,710억 개에 달하지만, 각 토큰을 처리할 때 실제로 활성화되는 파라미터는 370억 개에 불과합니다.
DeepSeek-V3의 MoE 구조에는 두 가지 유형의 전문가(expert)가 있는데요. 위 그림에서 초록색 부분에 해당하는 Shared Expert와 하늘색 부분에 해당하는 Routed Expert입니다. Shared Expert는 모든 토큰에 대해 항상 활성화되는 전문가입니다. 주로 공통적인 언어 규칙이나 기본적인 문법과 같은 일반적인 지식을 처리하는 역할을 담당합니다. 모든 토큰이 거쳐야하는 기본 처리 과정을 담당하기 때문에, 모델의 안정성과 효율성을 높이는 데 기여합니다. 반면, Routed Expert는 토큰별로 다르게 선택되어 활성화됩니다. 여기에서는 코딩, 수학, 특정 도메인 지식 등 특화된 영역에 대한 정보를 처리합니다. 논문에 따르면, MoE layer당 1개의 Shared Expert와 256개의 Routed Expert가 있습니다. 그리고 각 토큰에 대해 256개의 Routed Expert 중 8개의 전문가가 선택되어 활성화됩니다.
1.2 Multi-head Latent Attention (MLA)
 Multi-head Attention
Multi-head Attention
 Grouped-query Attention
Grouped-query Attention
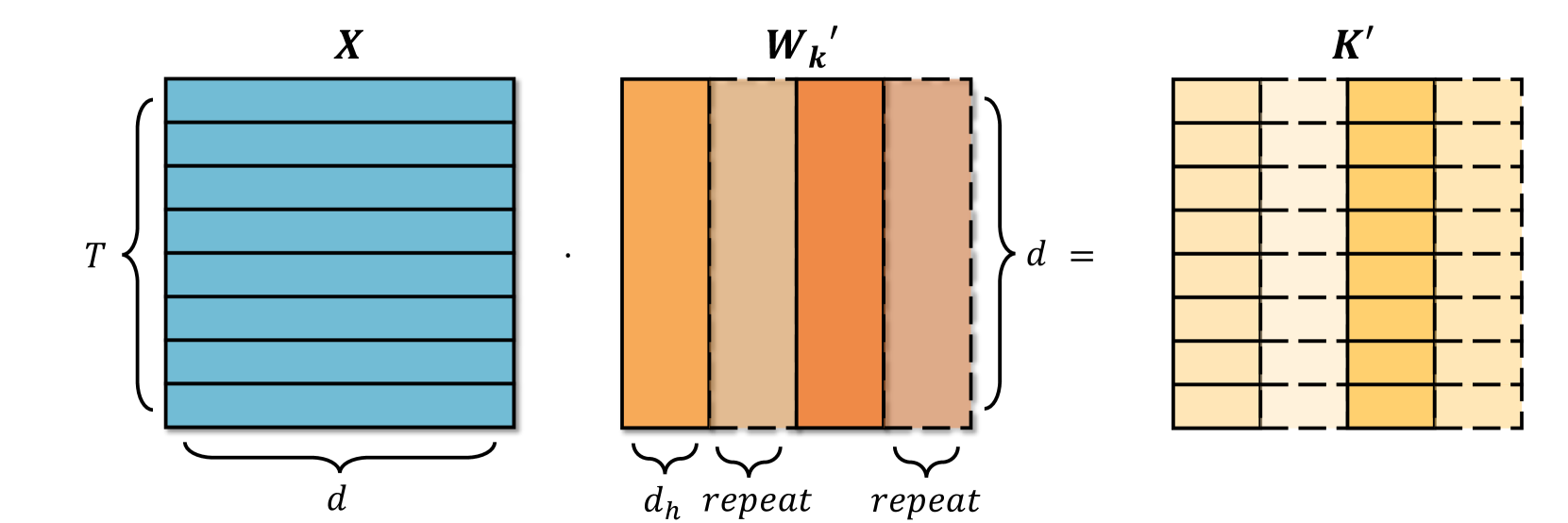
기존 Transformer 모델의 Multi-head Attention (MHA)은 모든 토큰의 Key와 Value를 메모리에 저장하고 계산합니다. 모델의 크기가 커질수록 이 Key-Value 캐시의 크기가 기하급수적으로 늘어나, GPU 메모리가 부족해지는 문제가 발생합니다. 이를 해결하기 위해 Query를 여러 그룹으로 나누고 그룹별로 Key, Value를 공유하는 Grouped-query Attention (GQA) 구조가 제안되기도 했습니다.
 Multi-head Latent Attention
Multi-head Latent Attention
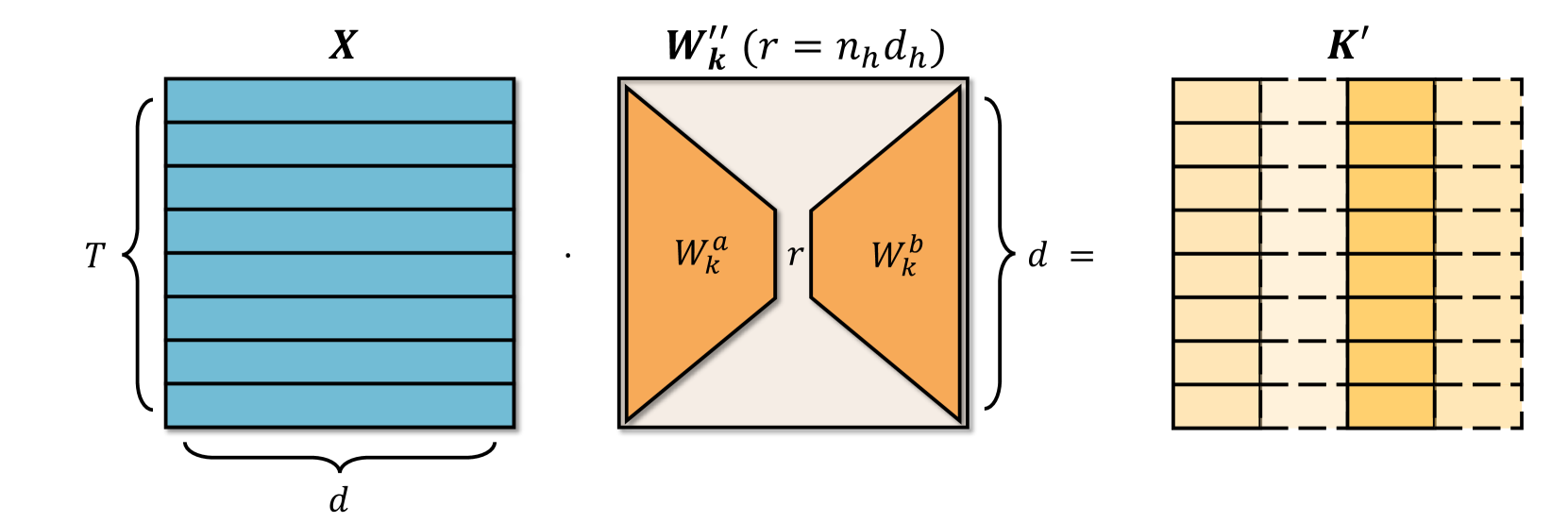
DeepSeek-V3에서는 Multi-head Latent Attention (MLA)를 사용했는데요. Key-Value 캐시 메모리를 기존 MHA 방식보다 60배, GQA 방식보다 12배나 절약할 수 있는 방법입니다. MLA가 이렇게 획기적으로 캐시 메모리를 절약할 수 있는 것은 Key, Value vector를 저차원의 latent vector로 압축하여 저장하기 때문입니다. 입력 토큰을 $\mathbf{h}_t$, 입력 토큰을 압축시키는 down-projection matrix를 $W^{DKV}(W_k^a)$, 압축된 vector를 다시 확장하는 up-projection matrix를 $W^{UK}(W_k^b)$라 하면 MLA의 Key, Value 압축 과정은 다음과 같습니다.
Key, Value 압축
먼저, 입력 토큰 $\mathbf{h}_t$를 $W^{DKV}$를 통해 압축하고, 이 압축된 vector $\mathbf{c}_t^{KV}$를 캐시에 저장합니다. $\mathbf{c}_t^{KV}$의 차원 $r$은 원래 차원 $d$보다 훨씬 작습니다. Key와 Value는 동일한 down-projection matrix $W^{DKV}$를 공유해서 하나의 저차원 vector를 만드는데, 이 부분이 MLA의 핵심입니다.
\[\mathbf{c}_t^{KV}=W^{DKV}\mathbf{h}_t \in \mathbb{R}^r \tag{1}\]압축된 vector $\mathbf{c}_t^{KV}$를 $W^{UK}$와 $W^{UV}$를 통해 확장합니다. 이 때, up-projection matrix는 공유하지 않습니다. 차원이 일치해야 Attention 계산이 가능하므로, 압축된 vector를 다시 원래 차원 $d$로 확장하는 과정이 필요합니다. 실제 Attention 계산을 할 때는 확장된 Key vector $\mathbf{k}_t^{C}$와 Value vector $\mathbf{v}_t^{C}$를 사용하는 것입니다.
\[[\mathbf{k}_{t,1}^C;\mathbf{k}_{t,2}^C,\dots,\mathbf{k}_{t,n_h}^C]=\mathbf{k}_t^{C}=W^{UK} \mathbf{c}_t^{KV}\] \[[\mathbf{v}_{t,1}^C;\mathbf{v}_{t,2}^C,\dots,\mathbf{v}_{t,n_h}^C]=\mathbf{v}_t^{C}=W^{UV} \mathbf{c}_t^{KV}\]위 그림에서는 표현되지 않았지만, 입력 토큰에 $W^{KR}$를 곱해서 특정 차원의 공간으로 projection한 뒤에 RoPE를 적용합니다. 이렇게 위치 정보가 적용된 $\mathbf{k}_t^{R}$를 압축된 vector $\mathbf{c}_t^{K}$와 분리하여 캐시에 저장합니다. Value vector에는 RoPE를 적용하지 않는데, 그 이유는 attention score $Q \cdot K^T$를 계산할 때 이미 위치 정보가 반영되었기 때문입니다.
\[\mathbf{k}_t^{R}=\text{RoPE}(W^{KR}\mathbf{h}_t) \tag{2}\] \[\mathbf{k}_{t,i}=[\mathbf{k}_{t,i}^C;\mathbf{k}_t^R]\]결론적으로, 식 (1)과 (2)에 해당하는 압축된 vector $\mathbf{c}_t^{KV}$와 위치 정보가 적용된 $\mathbf{k}_t^{R}$만 캐시에 저장됩니다.
Query 압축
Key와 같은 방식으로, 입력 토큰 $\mathbf{h}_t$를 $W^{DQ}$를 통해 압축합니다. Query는 매번 새로 계산되고 사용 즉시 버려집니다.
\[\mathbf{c}_t^{Q}=W^{DQ}\mathbf{h}_t\]압축된 vector $\mathbf{c}_t^{Q}$를 $W^{UQ}$를 통해 확장합니다. 이 확장된 Query vector $\mathbf{q}_t^{C}$가 Attention 계산에 사용됩니다.
\[[\mathbf{q}_{t,1}^C;\mathbf{q}_{t,2}^C,\dots,\mathbf{q}_{t,n_h}^C]=\mathbf{q}_t^{C}=W^{UQ} \mathbf{c}_t^{Q}\]입력 토큰에 $W^{QR}$를 곱해서 projection한 뒤 RoPE를 적용합니다.
\[[\mathbf{q}_{t,1}^R;\mathbf{q}_{t,2}^R,\dots,\mathbf{q}_{t,n_h}^R]=\mathbf{q}_t^{R}=\text{RoPE}(W^{QR} \mathbf{c}_t^{Q})\] \[\mathbf{q}_{t,i}=[\mathbf{q}_{t,i}^C;\mathbf{q}_{t,i}^R]\]Attention 계산
\[\mathbf{o}_{t,i} = \sum_{j=1}^{t} \operatorname{Softmax}_j\!\left( \frac{\mathbf{q}_{t,i}^{\top}\mathbf{k}_{j,i}} {\sqrt{d_h + d_h^{R}}} \right)\, \mathbf{v}^{C}_{j,i}\] \[\mathbf{u}_{t} = W^{O}\,[\,\mathbf{o}_{t,1};\,\mathbf{o}_{t,2};\,\dots;\,\mathbf{o}_{t,n_h}\,]\]위 수식에서 Softmax 값이 attension score $\alpha$이고, 이 값을 가중치로 사용해 Value를 가중합 한 것이 $\mathbf{o}_{t,i}$입니다. $\mathbf{u}_t$는 모든 head의 attention 결과를 이어 붙인 다음 $W^O$로 projection한 것입니다.
2. Post-Training
2.1 DeepSeek-R1-Zero
이전 포스트에서 다룬 Llama 3와 같은 일반적인 LLM은 Pre-training 후에 Supervised Fine-Tuning (SFT)과 강화 학습(RLHF)을 거쳐 성능을 개선합니다. DeekSeek 연구팀은 라벨링된 데이터 없이, 순수 강화 학습만으로 추론 능력을 향상시킬 수 있을지 LLM의 잠재력을 탐구해보고자 했습니다. 이를 위해 학습된 모델이 DeepSeek-R1-Zero 입니다. 먼저, 프롬프트는 아래와 같이 <think>…</think>와 <answer>…</answer> 포맷만 지시하고, 특정 해결 전략을 강제하지 않습니다.

강화 학습 기법으로는 Group Relative Policy Optimization (GRPO)를 사용했습니다. 학습 과정은 아래와 같습니다.
Step 1각각의 질문 $q$에 대해 구 정책 $\pi_{\text{old}}$로 $G$개 응답 $o_i$를 샘플링합니다.Step 2각 응답마다 정확도 보상과 포맷 보상으로 스칼라 보상 $r_i$를 계산합니다. 정확도 보상은 규칙 기반 검증으로 응답이 정확한지를 측정하는 것이고, 포맷 보상은 <think>…</think>와 <answer>…</answer> 포맷을 잘 지켰는지 보는 것입니다.Step 3$G$개의 응답 평균을 기준선으로 보상을 상대화해서 그룹 정규화 어드밴티지 $A_i$를 계산합니다.
Step 4PPO-clip 형태의 목적 함수에 레퍼런스 정책과의 KL penalty를 추가해 정책 $\pi_{\theta}$를 업데이트 합니다. 여기에서 레퍼런스 정책은 DeepSeek-V3-Base 모델입니다.
Step 5정책 업데이트 후 $\pi_{\text{old}}$를 $\pi_{\theta}$로 교체합니다.
2.2 DeepSeek-R1
하지만 DeepSeek-R1-Zero은 가독성이 떨어지거나 여러 언어가 섞여 나타나는 등의 문제가 있었습니다. 이러한 문제를 해결하기 위해 제안된 모델이 DeepSeek-R1입니다. DeepSeek-R1은 다음과 같이 네 단계로 진행됩니다.
Cold Start: 길이가 긴 Chain of Thought (CoT) 데이터를 수집하여 DeepSeek-V3-Base 모델을 fine-tuning합니다. 이를 통해 강화 학습의 불안정한 초기 단계를 방지합니다.Reasoning-oriented Reinforcement Learning: DeepSeek-R1-Zero와 동일한 대규모 강화 학습을 실행합니다. 이 단계에서는 모델의 추론 능력을 향상시키는 데 집중합니다.Rejection Sampling and SFT: 추론 지향 강화 학습이 수렴하면, 그 결과로 얻은 체크포인트를 활용해 데이터를 수집하고 모델을 다시 fine-tuning합니다. 추론에 초점을 맞추었던 cold start 데이터와 달리, 쓰기, 롤플레잉, 기타 범용 작업 등 다른 도메인의 데이터가 포함됩니다. 약 80만 개의 데이터셋으로 모델을 2 epoch 학습시킵니다.Reinforcement Learning for all Scenarios: 유용성과 안전성 측면에서 모델을 개선하고, 추론 능력을 정제하기 위해 두 번째 강화 학습을 실행합니다. 이는 모델을 사람의 선호에 맞추는 과정입니다.
3. Knowledge Distillation
DeepSeek-R1을 사용해 생성한 80만 개의 데이터로 Qwen과 Llama 3 모델을 fine-tuning해서 DeepSeek-R1의 추론 패턴을 Knowledge Distillation으로 이식했습니다. 이는 지난 포스트에서 다룬 적 있는 Alpaca와 유사한 방식입니다.
4. 모델 성능
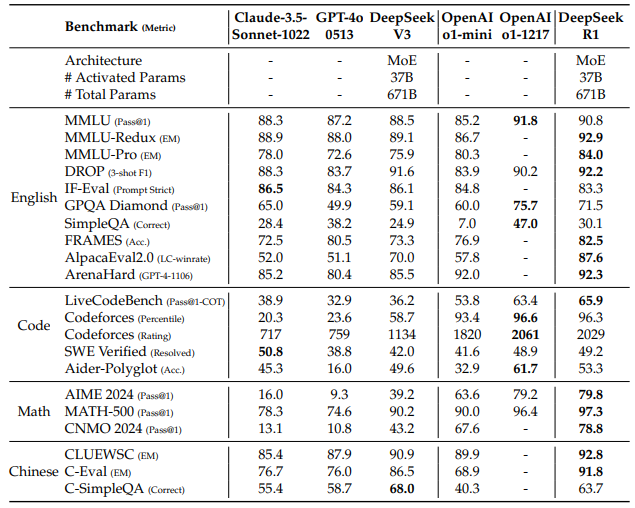
DeepSeek-R1은 거의 모든 영역에서 DeepSeek-V3보다 개선된 성능을 보입니다. 또한 최신 사용 모델들과도 견줄 만한 뛰어난 성능을 달성했습니다.