[Paper Review] CLIP: Learning Transferable Visual Models From Natural Language Supervision
CLIP은 OpenAI에서 발표한 멀티모달 모델입니다. Contrastive learning 방식으로 텍스트와 이미지를 함께 학습시켜서, 둘을 같은 embedding space에서 비교하거나 연결할 수 있도록 만들었습니다. 인식해야 할 클래스의 이름만 주어지면, 어떤 벤치마크에도 적용할 수 있는 우수한 Zero-shot 성능을 보인다는 점에서 주목할 만한 모델입니다.
1. 학습 데이터
전통적인 이미지 분류 모델은 라벨링된 데이터를 필요로 합니다. 이미지 하나하나에 대해서 작업자가 미리 정해둔 클래스 중 하나를 라벨로 선택해야 하는데, 이러한 작업은 많은 비용과 시간이 소요된다는 단점이 있습니다.
CLIP은 수작업 라벨링 없이 인터넷에서 수집한 이미지와 텍스트(캡션)을 학습 데이터로 사용했습니다. 인터넷에 공개된 (이미지, 텍스트) 쌍 중에서 텍스트가 50만 개의 쿼리 중 하나를 포함하는 경우만 필터링해서 총 4억 쌍의 데이터셋을 만들었습니다. 여기에서 쿼리 리스트는 위키피디아에 100회 이상 등장하는 단어들, 자주 등장하는 2-gram, 검색량이 많은 위키피디아 문서 제목, 동의어 집합으로 구성되어 있습니다. 그리고 쿼리당 2만 쌍의 데이터만 수집해서 균형을 맞췄습니다.
| 발표 시기 | 논문 | 데이터셋 규모 | 비고 |
|---|---|---|---|
| 2016 | YFCC100M | 99M | |
| 2017 | Visual N-Grams | 30M | YFCC100M 중 영어 코멘트만 필터링 |
| 2018 | Conceptual Captions | 3.3M | |
| 2021 | VirTex | 0.6M | COCO Captions dataset 118K 이미지 × 5 캡션 |
| 2021 | CLIP | 400M |
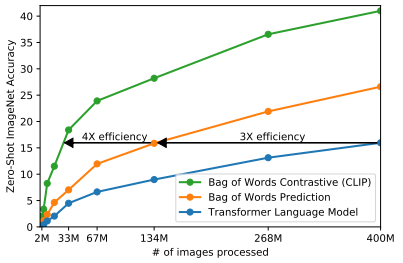
CLIP 이전에도 이미지와 텍스트 쌍을 학습 데이터로 쓴 연구는 많았지만, CLIP 만큼 대규모 데이터셋을 사용하지는 않았습니다. 저자들은 이렇게 데이터 규모를 확대한 것이 모델의 Zero-shot 성능을 끌어올린 핵심 요인임을 강조합니다. 아래 표에서 학습 이미지가 늘어날수록 Zero-shot 정확도가 꾸준히 상승하는 것을 확인할 수 있습니다.
2. 모델 구조
Pre-training
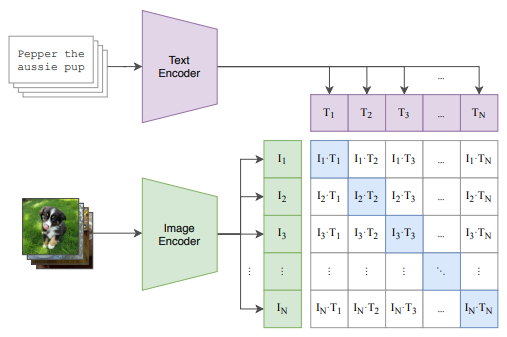 Contrastive pre-training
Contrastive pre-training
배치 당 $N$개의 (이미지, 텍스트) 쌍 데이터가 있을 때, 어떤 텍스트가 어떤 이미지와 짝을 이루는지 positive pair를 맞추는 task를 통해 모델이 학습됩니다. 모델 학습 과정을 정리해 보면 아래와 같습니다.
Step 163M 크기의 Transformer(Text Encoder)에 텍스트를 입력해 $N$개 텍스트 데이터 각각의 embedding을 구합니다.Step 2마찬가지로 이미지도 ResNet-50/ViT(Image Encoder)에 입력해 embedding을 구합니다.Step 3텍스트 embedding과 이미지 embedding 사이의 유사도를 계산합니다.Step 4텍스트 방향, 이미지 방향 모두에 대해서 InfoNCE loss를 구해서 두 loss의 평균 값을 최종 loss로 사용합니다.
위 과정을 반복하면 positive pair의 유사도는 최대화되고, negative pair의 유사도는 최소화되는 방향으로 모델이 학습됩니다.
Zero-shot prediction
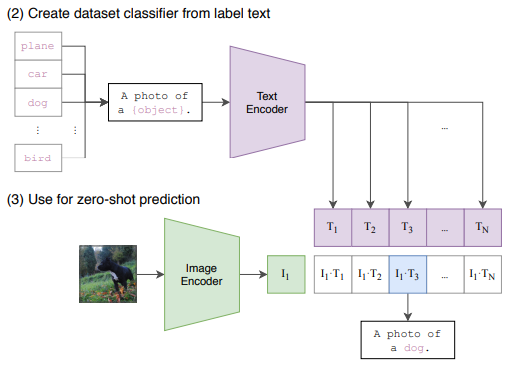
앞서 잠깐 언급한 것처럼, CLIP은 높은 Zero-shot 성능이 특징인 모델입니다. 새로운 벤치마크를 평가할 때는 인식해야 할 클래스의 리스트 {plane, car, dog, … , bird} 만 준비하면 됩니다. 그런데 pretrain 시에 학습시킨 데이터셋에서는 텍스트가 보통 한 문장이라서 단어만 입력되면 분포에 차이가 생기게 됩니다. 이를 막기 위해 “A photo of a {object}.“라는 기본 프롬프트를 사용해서 단어를 문장으로 바꾸고, 이를 Text Encoder에 입력해 embedding을 구합니다. 이 과정은 한 번만 수행해서 텍스트 embedding을 캐싱해두고, 이후 모든 이미지 예측에 재사용합니다.
이렇게 분류기가 준비되면, 예측할 이미지를 Image Encoder에 입력해서 이미지 embedding을 구합니다. 그리고 텍스트 embedding과의 유사도를 계산해서 유사도가 가장 높은 문장을 찾습니다.
3. 모델 성능
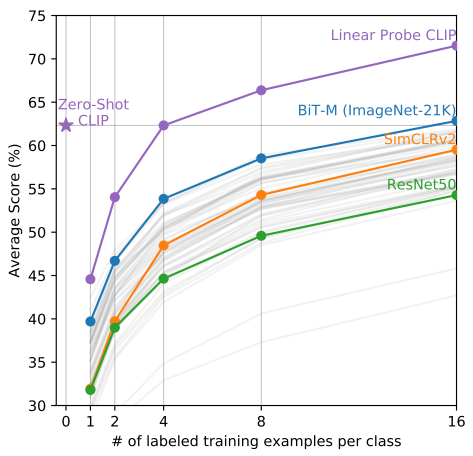
위 그래프는 CLIP의 Zero-Shot 성능(★)과 CLIP으로 학습한 representation을 freeze하고 softmax classifier를 붙여 Few-Shot 성능을 측정한 결과(Linear Probe CLIP), 그리고 다른 공개 모델들(BiT-M, SimCLRv2, ResNet50)의 Few-Shot 성능을 비교한 것입니다. CLIP의 Zero-Shot 성능이 다른 모델들의 Few-Shot 성능보다 대체로 높게 나타났습니다. 또한 CLIP의 Zero-Shot 성능은 4-shot과 비슷하고, 8-shot에도 근접한 성능을 보였습니다. Zero-Shot 성능이 여러 example을 사용해서 softmax classifier를 별도로 학습해야만 얻을 수 있는 성능에 도달한 것입니다.
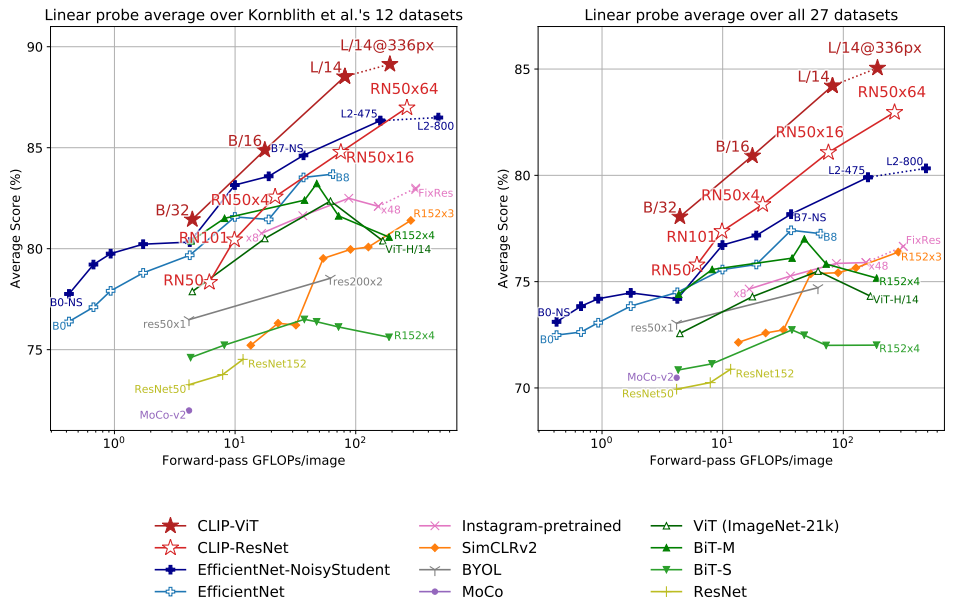
위 그래프는 다양한 모델의 Linear Probe 성능을 비교한 결과입니다. CLIP은 모델 크기를 키울수록 Linear Probe 성능이 꾸준히 상승했습니다. $x$축은 이미지 한 장을 추론하는 데 소요되는 연산량을 나타냅니다. 이 값이 작을 수록 가벼운 모델이고, 클 수록 무거운 모델입니다. 동일 연산량 기준 CLIP이 기존 SOTA보다 높은 정확도를 달성했습니다. 또한 CLIP-ResNet보다 CLIP-ViT이 연산 효율이 약 3배 높게 나타났습니다. 좌측 그래프를 살펴보면, CLIP-ViT-B/16 모델과 CLIP-ResNet50x16 모델은 약 85%의 정확도로 비슷한 성능을 보이지만 CLIP-ViT-B/16 모델이 훨씬 적은 계산량으로 동일한 성능을 달성한 것을 확인할 수 있습니다.